How I do My Research (As a PhD Student)
Date: 2025-03-16
Last Updated:
How I do My Research (As a PhD Student)
It has almost become a cliche amongst a certain kind of PhD student to explain
Exactly your research workflow, and why it works. Now it is my turn to add to
the pile.
The overall "philosophy" (If you can even call it that) of my Pesonal Knowledge
Management (PKM) system, is minimising friction by allowing emergence. What that
means, is I just use the tools in front of me, and only create systems which
support my habbits, rather than fighting them - If a process is not the easiest
way of doing it in the short term, then eventually I will skip it when I am tired/lazy/bored.
This is not what we want, so instead lets so remove all friction from the process.
There is one exception to my zero friction rule. Everything that goes into
my "Second Brain" needs to be written by me. Not copy and pasted, and not by AI.
This isn't for any political or philosophical reason. It’s simply because I
understand things better when I put them in my own words, and my Vault is only
for things I have understood.
1 Technologies
1.1 Obsidian

I don't know how you would have found this post if you do not know Obsidian. Just in case, I will give you a run down on what it is, and why it is perfect for a brain like me.
Obsidian is a text editor, which supports links, back-links and a whole bunch of plug-ins.
It saves every note you take in plain text on your own computer. No cloud BS, no
proprietary file format BS. Just text. This is important, because it means my
notes will outlive Obsidian. If the program is enshitified
, I can easily port them over to another program (I've been keeping a close eye on
Neovim and Emacs).
The power of Obsidian from a knowledge management perspective,
comes from its ability to manage connections. It supports links just like
Wikipedia, so I am able to "surf my vault". A feature Extremely handy for when
I half remember something that I am sure that I wrote down somewhere once. It also
works backwards, where from a given note, I can quickly see every note which links
TO it.
1.1.1 Plug-ins
1.1.1.1 Dataview
I don’t use Dataview that much. Mostly, I use it in my daily notes. It lets me search for every note created and last modified on a given date, basically letting me browse my notes over time.
1.1.1.2 Excalidraw
I was extremely skeptical of introducing Excalidraw to my system. Isn't this a proprietary file format that I will be Shit out of luck if they enshittify? Not quite. The excalidraw plugin lets you export them as .svg. So all my drawings are first exported to SVG and then linked into the relevant note.
This means if they every enshittify, I can go and edit them in InkScape. Not the best solution, but I am definitely not stuck with them.
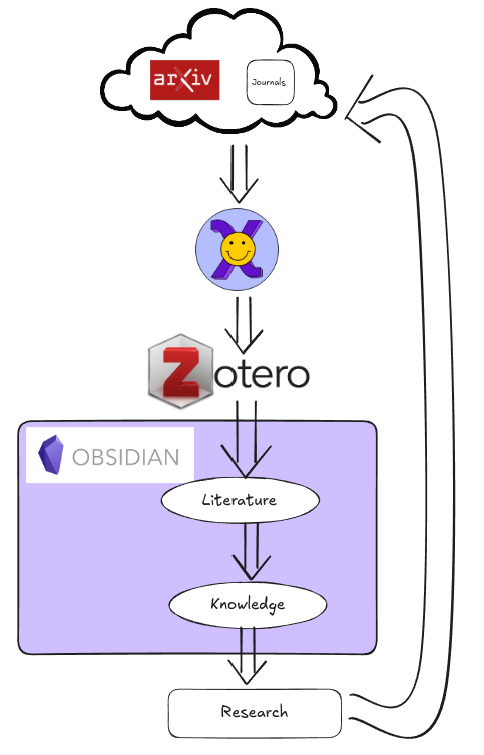
1.2 Zotero

Zotero is a freee and open source citations manager. What this means in practice, is it becomes a library of every PDF for every paper I read, with all the bibliographic details logged.
1.3 Git and GitHub

My Obsidian vaults are synchronised between my devices using Github. This solution is a little jankier than the premium obsidian feature, but it is free.
The biggest hurdle to lookout for, is concurrent edits on different devices will almost always create a git merge conflict that will be a nightmare to fix. I have accidentally nuked my vault trying to fix it before (thank god for frequent back ups lol). So, make sure you finish editing, commit and push on one device, before opening on another! (or just pay for the premium feature)
1.4 Synology Diskstation NAS
This networked Access Storage Device, is where all my local backups go. It is essentially an external hard drive which plugs into an Ethernet port in my house. Then every networked device in my house, including my computers, phone, tablet and my partners devices, see it as an attached hard-drive.
I use automatic backups to move everything important onto this regularly.
2 The workflow!
2.1 Literature Review
The first step, after identifying relevant papers (see the secret step for more details), is to throw the paper into my Zotero database.
Whenever I want to read a paper, Zotero downloads it, grabs the bibliographic information, and saves it all. Once it’s in Zotero, the BetterBibTex plugin will append the details to a .bib file.
Next, I open the PDF in Zotero and switch over to Obsidian. Using the Citations plugin, I tell it to read that .bib file, and it creates a new note for the paper. I have a template set up that automatically puts the relevant details in the heading and pulls the abstract to the top of the note.
Now the actual study begins. How deeply I go depends on how interesting the paper is. At a minimum, I’ll:
- Link the paper to at least one "parent" note, representing the topic of the paper. For example, a paper about photonic lantern wavefront sensors would be linked to my notes on photonic lanterns and wavefront sensors.
- Write a few bullet points summarizing the main point of the paper, or what I thought was important.
- Screenshot and copy all the figures into my Vault.
From here, if it is an important paper, I will do a close reading, and paraphrase important parts out of the paper into my notes.
2.1.1 Secret Step ChiScraper
This tool I built myself was massively helpful for the early stages of my PhD where I was doing a heap of reading and trying to catch up with the state of research. The website and blogpost explains it in detail, but essentially, this tool filters and ranks articles from the ArXiv, and shows me the papers which are most relevant to me.
If you're a researcher who doesn't use the ArXiv but want to use this tool, ask me nicely and I'll add options for other sources. I have just let the project go into hibernation while it fits my use case for now.
Check out the project here and the blog post here
2.2 Knowledge Forming
I consider notes from literature only half processed. They’re fully
processed once I’ve abstracted the knowledge and distilled it into the
relevant “parent” notes. This means I have two types of notes:
| Knowledge Notes | Literature Notes |
|---|---|
| - Composed from many sources | - Composed from a single source |
| - Broad basis of knowledge, links to many other ideas liberally. | - Knowledge is specific to the source's study |
For example, I have a note on Photonic Lantern Wavefront Sensors which contains everything I know about them, or links to sub-notes with that information (like PL-WFS Reconstruction Techniques). The information in this note should have appropriate citations, with links pointing to the relevant literature notes.
These are the notes I go to when I need to remember something. If I ever find the info I need in a literature note, that’s a sign it should be in a knowledge note, and I copy it over immediately.
When I write these knowledge notes, I use links extensively. At a minimum, I'll link to a "parent" note (one level up in abstraction). For example, Photonic Lantern Wavefront Sensors will have links to Photonic Lanterns and Wavefront Sensors. I’ll also link to relevant concepts as they come up: proofs, theorems, principles, etc. And often I’ll have a "See Also" section with links to other relevant notes.
These knowledge notes are where 90% of the content of my notes lives.
2.3 Structured Notes
I also have a few templates for specific types of notes.
2.3.1 Daily and Weekly Notes
These are mainly scratchpads for temporary information: phone numbers, links, etc. The most important part is the Dataview queries which find every note created on a given day. This lets me quickly skim through my notes over time.
2.3.2 People
I have notes for people – coworkers, networking contacts, etc. Not much usually goes in these notes; they mostly exist as a place to link to, and to see backlinks from.
2.3.3 Meetings
When I take notes during a meeting, the first thing I do is link to the people notes for all attendees. This lets me quickly check every meeting I’ve had with someone by looking at their person note and checking the backlinks.
3 Making Sense of the Chaos
Okay, so that’s how I get knowledge into my system. How do I get it out?
Links, mostly!
Obsidian’s search is super fast and great. So, when I need a specific note,
a search will find it quickly. If I'm revisiting a topic I’ve already studied,
I can usually find a high-level note for it. From there, I “surf” the links,
re-reading until I find the relevant information. This is also an opportunity
to reshape and form new connections. If it took me a long time to find a specific
bit of information, I go back to what I originally searched for and add a link.
This means my “second brain” is constantly evolving - reformulating links and
connections, just like my first, meat based, brain.
Another example. Let's say I wanted to find info about training a Neural Network
on the outputs of a photonic lantern. This is covered in the paper
Sweeney, D. et,al. 2021. "Learning the lantern: neural network applications to broadband photonic lantern modeling"
, but let’s suppose I forgot this.
First, I’d pull up my note for Photonic Lanterns and skim it, where
I’d find a note for Photonic Lantern - Wavefront Sensor. From there,
I’d see the info on Photonic Lantern Reconstruction Algorithms and opening
that note, I’d find the stuff I wrote about NN-based photonic lantern output
approximation, along with a link to the relevant paper.
Here you can see where I can start with a fuzzy, half remembered idea, and quickly resurface a specific paper, rather than scratching my head trying to remember who wrote what from a cold start.
With any hope, this lets me do research and close the loop!
Conclusions
This is just a broad overview of physically HOW I do my research.
Maybe at some point later I will dive deeper into my philosphy of what deserves
a note and how I go about learning. But that is for another time.
This post was more inspried by the typical "Here is the tools I use" kind of posts
you see on other folks personal web pages. I hope you found it interesting, and
if you feel like chatting ping me an email or connnect on Mastodon!